GPU
Architecture taxonomy
GPU architectures can be classified as sort-first, sort-middle (Tile-based rendering), sort-last fragment, and sort-last image:
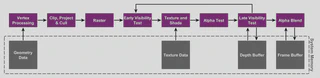
Immediate mode rendering
Desktop GPUs are based on Immediate mode rendering (IMR) architecture, which process rendering as a strict command stream, executing the vertex and fragment shaders in sequence on each primitive in every draw call:
High-level pseudo-code example of this approach:
for draw in render pass:
for primitive in draw:
for vertex in primitive:
ExecuteVertexShader(vertex)
if primitive not culled:
for fragment in primitive:
ExecuteFragmentShader(fragment)
Advantage
The output of the vertex shader, and other geometry related shaders, can remain on-chip inside the GPU. The output of these shaders can be stored in a FIFO buffer until the next stage in the pipeline is ready to use the data. This means that the GPU uses little external memory bandwidth storing and retrieving intermediate geometry results.
Disadvantage
The fragment shading jumps around the screen depending on the locations of the triangles in each draw. This happens because any triangle in the stream may cover any part of the screen and triangles are processed in draw order. The effect of this means that the active working set is the size of the entire framebuffer. The GPU must fetch from this working set the current value of the data for the pixel coordinate of the current fragment for every blending, depth testing, and stencil testing operation.The bandwidth load placed on this memory can be very high because of multiple read-modify-write operations for each fragment. This results in higher power consumption.
Reference
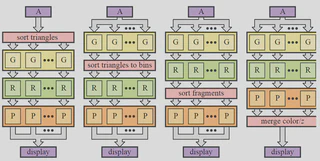
Tile-based deferred rendering
Mobile GPUs are based on Tile-based Deferred Rendering (TBDR) architecture, which splits the screen into a number of tiles and fragment shade each small tile to completion before writing it out to memory:
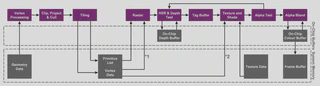
TBDR combines two complementary architectural features to provide the very highest levels of efficiency and performance:
- Tile-based rendering
- Deferred rendering
Tile-based rendering
The first pass executes all the geometry related processing, and generates a tile list data structure (Visiblity stream from Qualcomm, Per-tile list from Arm, Primitive list from Imagination) that indicates what primitives contribute to each screen tile. The second pass executes all the fragment processing, tile by tile, and writes tiles back to memory as they have been completed.
High-level pseudo-code example of this approach:
# Pass one
for draw in render pass:
for primitive in draw:
for vertex in primitive:
ExecuteVertexShader(vertex)
if primitive not culled:
AppendTileList(primitive)
# Pass two
for tile in render pass:
for primitive in tile:
for fragment in primitive:
ExecuteFragmentShader(fragment)
Deferred rendering
Deferred rendering uses method (Early Z rejection from Qualcomm, Forward pixel killing from Arm, Hidden Surface Removal from Imagination) which defers all texturing and shading operations until the visibility of each pixel in the tile is known – only the pixels that will actually be seen by the end user consume processing resources.
Advantage
This approach is designed to minimize the amount of external memory accesses the GPU needs during fragment shading. Since the GPU only needs to work on a subset of the complete scene data at any given time, this data (such as colour and depth buffers) is small enough to be stored in internal GPU memory. GPUs only have to write the color data for a tile back to memory once rendering is complete, significantly reducing the required number of accesses to system level memory. This results in lower bandwidth consumption.
Texture cache performance can be improved textures covering multiple primitives may be accessed more coherently one tile at a time than one primitive at a time.
Much less on-chip space is needed for good performance compared with a general-purpose frame buffer cache. This means that more space can be dedicated to texture cache, further reducing bandwidth.
Unnecessary processing of hidden pixels is eliminated. This results in lower power consumption.
Disadvantage
Framebuffer reads that might fall outside the current fragment are relatively more costly.
There is a cost to traversing the geometry repeatedly.
Reference
- Qualcomm developer
- Snapdragon game toolkit
- Arm developer
- Arm GPU best practices developer guide
- Tile-based rendering
- Imagination developer
- PowerVR graphics architectures
- Samsung developer
- Galaxy game development
- GPU Hardware and Parallel Rasterization
- IMR, TBR, TBDR and some understanding of GPU architecture
- Summary of GPU architecture knowledge for mobile devices